CUDA and the parallel processing power of GPUs.
CUDA is a parallel computing platform and programming model developed by Nvidia for general computing on its own GPUs (graphics processing units). CUDA enables developers to speed up compute-intensive applications by harnessing the power of GPUs for the parallelizable part of the computation.
While there have been other proposed APIs for GPUs, such as OpenCL, and there are competitive GPUs from other companies, such as AMD, the combination of CUDA and Nvidia GPUs dominates several application areas, including deep learning, and is a foundation for some of the fastest computers in the world.
Graphics cards are arguably as old as the PC—that is, if you consider the 1981 IBM Monochrome Display Adapter a graphics card. By 1988, you could get a 16-bit 2D VGA Wonder card from ATI (the company eventually acquired by AMD). By 1996, you could buy a 3D graphics accelerator from 3dfx Interactive so that you could run the first-person shooter Quake at full speed.
Also in 1996, Nvidia started trying to compete in the 3D accelerator market with weak products but learned as it went, and in 1999 introduced the successful GeForce 256, the first graphics card to be called a GPU. At the time, the principal reason for having a GPU was for gaming. It wasn’t until later that people used GPUs for math, science, and engineering.
The origin of CUDA
In 2003, a team of researchers led by Ian Buck unveiled Brook, the first widely adopted programming model to extend C with data-parallel constructs. Buck later joined Nvidia and led the launch of CUDA in 2006, the first commercial solution for general-purpose computing on GPUs.
OpenCL vs. CUDA
CUDA competitor OpenCL was launched by Apple and the Khronos Group in 2009, in an attempt to provide a standard for heterogeneous computing that was not limited to Intel/AMD CPUs with Nvidia GPUs. While OpenCL sounds attractive because of its generality, it hasn’t performed as well as CUDA on Nvidia GPUs, and many deep learning frameworks either don’t support it or support it only as an afterthought once their CUDA support has been released.
CUDA performance boost
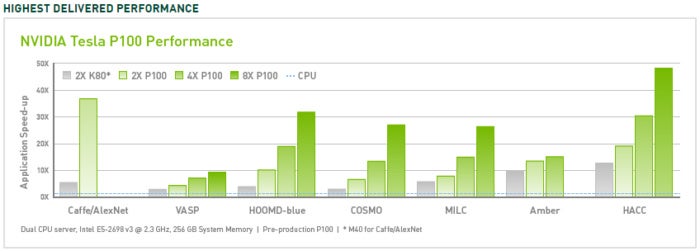
CUDA has improved and broadened its scope over the years, more or less in lockstep with improved Nvidia GPUs. As of CUDA version 9.2, using multiple P100 server GPUs, you can realize up to 50x performance improvements over CPUs. The V100 (not shown in this figure) is another 3x faster for some loads. The previous generation of server GPUs, the K80, offered 5x to 12x performance improvements over CPUs.
 Nvidia
Nvidia
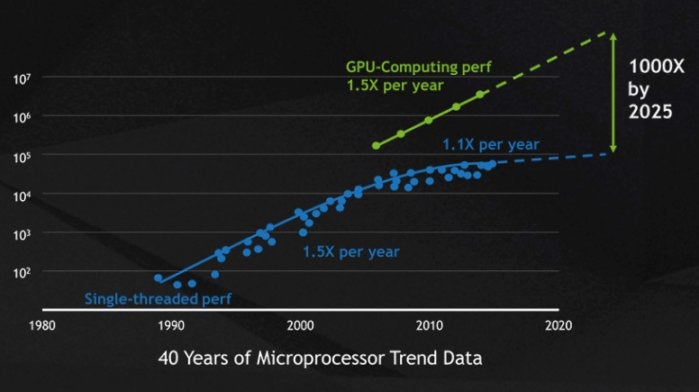
The speed boost from GPUs has come in the nick of time for high-performance computing. The single-threaded performance increase of CPUs over time, which Moore’s Law suggested would double every 18 months, has slowed down to 10 percent per year as chip makers encountered physical limits, including size limits on-chip mask resolution and chip yield during the manufacturing process and heat limits on clock frequencies at runtime.
 Nvidia
Nvidia
CUDA application domains
 Nvidia
Nvidia
CUDA and Nvidia GPUs have been adopted in many areas that need high floating-point computing performance, as summarized pictorially in the image above. A more comprehensive list includes:
- Computational finance
- Climate, weather, and ocean modeling
- Data science and analytics
- Deep learning and machine learning
- Defense and intelligence
- Manufacturing/AEC (Architecture, Engineering, and Construction): CAD and CAE (including computational fluid dynamics, computational structural mechanics, design and visualization, and electronic design automation)
- Media and entertainment (including animation, modeling, and rendering; color correction and grain management; compositing; finishing and effects; editing; encoding and digital distribution; on-air graphics; on-set, review, and stereo tools; and weather graphics)
- Medical imaging
- Oil and gas
- Research: Higher education and supercomputing (including computational chemistry and biology, numerical analytics, physics, and scientific visualization)
- Safety and security
- Tools and management
CUDA in deep learning
Deep learning has an outsized need for computing speed. For example, to train the models for Google Translate in 2016, the Google Brain and Google Translate teams did hundreds of one-week TensorFlow runs using GPUs; they had bought 2,000 server-grade GPUs from Nvidia for the purpose. Without GPUs, those training runs would have taken months rather than a week to converge. For production deployment of those TensorFlow translation models, Google used a new custom processing chip, the TPU (tensor processing unit).
In addition to TensorFlow, many other DL frameworks rely on CUDA for their GPU support, including Caffe2, CNTK, Databricks, H2O.ai, Keras, MXNet, PyTorch, Theano, and Torch. In most cases, they use the cuDNN library for the deep neural network computations. That library is so important to the training of the deep learning frameworks that all of the frameworks using a given version of cuDNN have essentially the same performance numbers for equivalent use cases. When CUDA and cuDNN improve from version to version, all of the deep learning frameworks that update to the new version see the performance gains. Where the performance tends to differ from framework to framework is in how well they scale to multiple GPUs and multiple nodes.
CUDA programming
 Nvidia
Nvidia
CUDA Toolkit
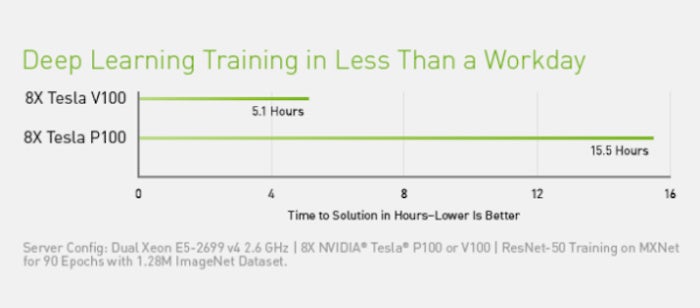
The CUDA Toolkit includes libraries, debugging and optimization tools, a compiler, documentation, and a runtime library to deploy your applications. It has components that support deep learning, linear algebra, signal processing, and parallel algorithms. In general, CUDA libraries support all families of Nvidia GPUs but perform best on the latest generation, such as the V100, which can be 3 x faster than the P100 for deep learning training workloads. Using one or more libraries is the easiest way to take advantage of GPUs, as long as the algorithms you need have been implemented in the appropriate library.
 Nvidia
Nvidia
CUDA deep learning libraries
In the deep learning sphere, there are three major GPU-accelerated libraries: cuDNN, which I mentioned earlier as the GPU component for most open source deep learning frameworks; TensorRT, which is Nvidia’s high-performance deep learning inference optimizer and runtime; and DeepStream, a video inference library. TensorRT helps you optimize neural network models, calibrate for lower precision with high accuracy, and deploy the trained models to clouds, data centers, embedded systems, or automotive product platforms.
 Nvidia
Nvidia
CUDA linear algebra and math libraries
Linear algebra underpins tensor computations and therefore deep learning. BLAS (Basic Linear Algebra Subprograms), a collection of matrix algorithms implemented in Fortran in 1989, has been used ever since by scientists and engineers. cuBLAS is a GPU-accelerated version of BLAS, and the highest-performance way to do matrix arithmetic with GPUs. cuBLAS assumes that matrices are dense; cuSPARSE handles sparse matrices.
 Nvidia
Nvidia
CUDA signal processing libraries
The fast Fourier transform (FFT) is one of the basic algorithms used for signal processing; it turns a signal (such as an audio waveform) into a spectrum of frequencies. cuFFT is a GPU-accelerated FFT.
Codecs, using standards such as H.264, encode/compress and decode/decompress video for transmission and display. The Nvidia Video Codec SDK speeds up this process with GPUs.
 Nvidia
Nvidia
CUDA parallel algorithm libraries
The three libraries for parallel algorithms all have different purposes. NCCL (Nvidia Collective Communications Library) is for scaling apps across multiple GPUs and nodes; nvGRAPH is for parallel graph analytics, and Thrust is a C++ template library for CUDA based on the C++ Standard Template Library. Thrust provides a rich collection of data parallel primitives such as scan, sort, and reduce.
Nvidia
CUDA vs. CPU performance
In some cases, you can use drop-in CUDA functions instead of the equivalent CPU functions. For example, the GEMM matrix-multiplication routines from BLAS can be replaced by GPU versions simply by linking to the NVBLAS library:
 Nvidia
Nvidia
CUDA programming basics
If you can’t find CUDA library routines to accelerate your programs, you’ll have to try your hand at low-level CUDA programming. That’s much easier now than it was when I first tried it in the late 2000s. Among other reasons, there is easier syntax and there are better development tools available. My only quibble is that on MacOS the latest CUDA compiler and the latest C++ compiler (from Xcode) are rarely in synch. One has to download older command-line tools from Apple and switch to them using Xcode-select to get the CUDA code to compile and link.
For example, consider this simple C/C++ routine to add two arrays:
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
You can turn it into a kernel that will run on the GPU by adding the __global__ keyword to the declaration, and call the kernel by using the triple bracket syntax:
add<<<1, 1>>>(N, x, y);
You also have to change your malloc/new and free/delete calls to cudaMallocManaged and cudaFree so that you are allocating space on the GPU. Finally, you need to wait for a GPU calculation to complete before using the results on the CPU, which you can accomplish with cudaDeviceSynchronize.
The triple bracket above uses one thread block and one thread. Current Nvidia GPUs can handle many blocks and threads. For example, a Tesla P100 GPU based on the Pascal GPU Architecture has 56 Streaming Multiprocessors (SMs), each capable of supporting up to 2048 active threads.
The kernel code will need to know its block and thread index to find its offset into the passed arrays. The parallelized kernel often uses a grid-stride loop, such as the following:
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
If you look at the samples in the CUDA Toolkit, you’ll see that there is more to consider than the basics I covered above. For example, some CUDA function calls need to be wrapped in checkCudaErrors() calls. Also, in many cases the fastest code will use libraries such as cuBLAS along with allocations of host and device memory and copying of matrices back and forth.
In summary, you can accelerate your apps with GPUs at many levels. You can write CUDA code; you can call CUDA libraries, and you can use applications that already support CUDA.
Source